关系型数据库(Mysql、Oracle)
优点
- 数据之间有关系,进行数据的操作时非常方便。
- 有事务操作,保证了数据的完整性。
缺点
- 因为数据和数据之间有关系的,而这种关系是由底层大量算法所保证。
- 数据的存储与使用,访问量大时IO的资源消耗较大。
- 大量算法会拉低系统的运行速度,并且会消耗系统资源。
- 在海量数据的增删改查时会显得无能为力,很可能会宕机。
- 在海量数据环境下对数据表进行维护、扩展,也会变得无能为力
例如:
update product set cname = ‘手机数码’;//修改所有数据
把商品表的cname字段,由varchar(64),char(100);//更改表字段属性非关系型数据库(NoSQL)
No不是单词no,是not only的缩写。设计之初是为了替代关系型数据库。足见其野心。优点
- 海量数据的增删改查,非常轻松
- 海量数据的维护非常轻松
缺点
- 数据与数据之间没有关系,所以不能一目了然
- 没有强大的事务,保证数据的完整和安全
redis概述
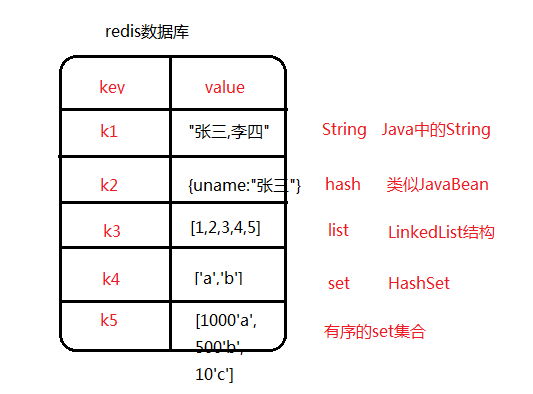
key-value结构的数据,类似Java中的Map,默认占用6379端口。共有5钟数据类型。string、hash、list、set、有序的set集合。
redis在Linux中的安装
redis是C语言开发,编译依赖gcc环境,需检查Linux环境是否有安装gcc

如果提示”bash: gcc: command not found”,则需要安装gcc环境。
命令:yum install gcc-c++
如果提示是否下载,输入y。
如果提示是否安装,输入y。
把redis的压缩文件上传至Linux服务器,解压的文件目录并进行编译
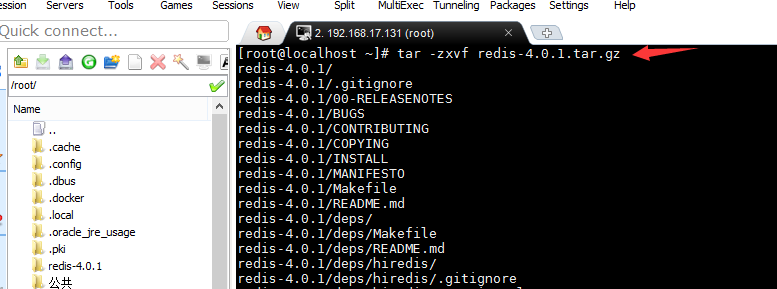
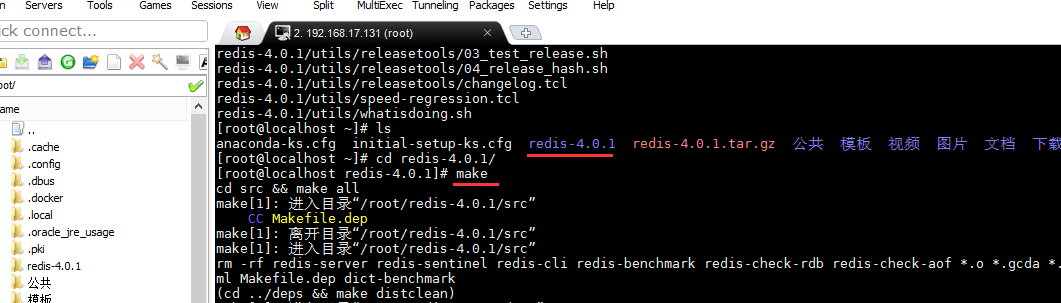
执行安装
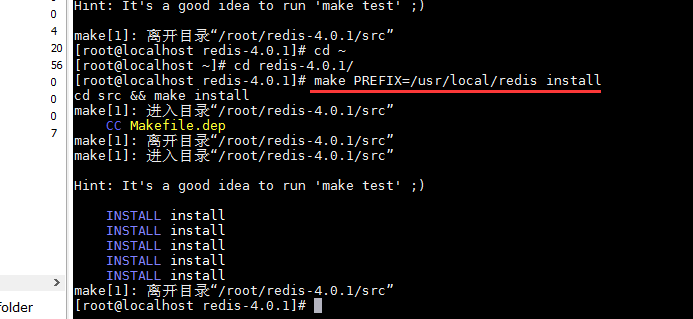
拷贝配置文件至安装目录中
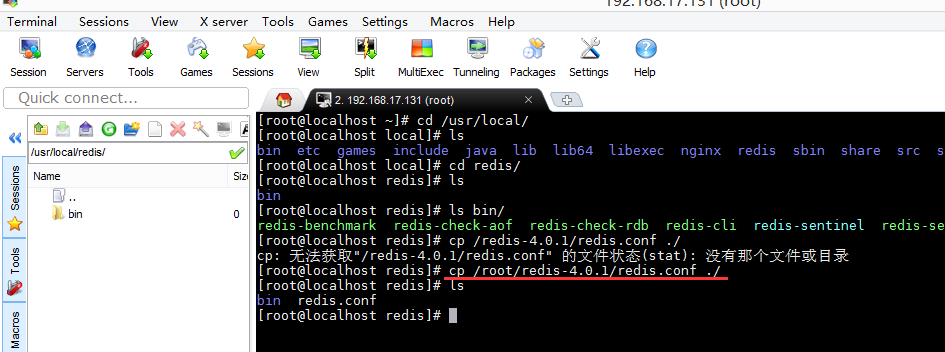
redis启动需要一个配置文件,可以修改端口号等配置。如果没有配置文件redis也可以启动,启用的是默认配置,不方修改端口号等配置。
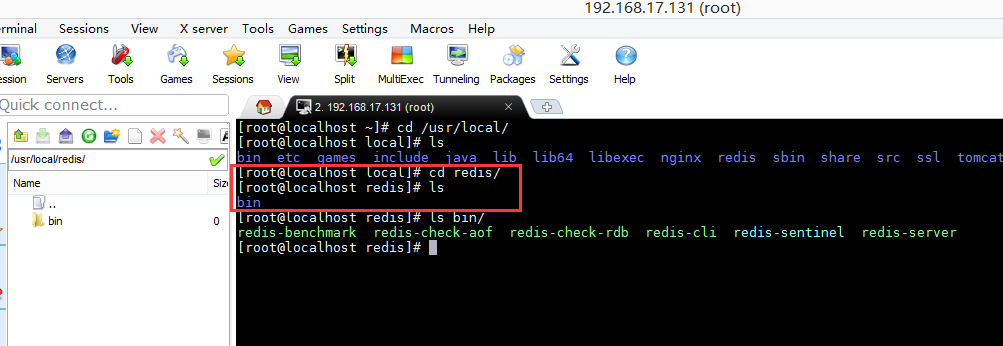
bin文件夹下的文件
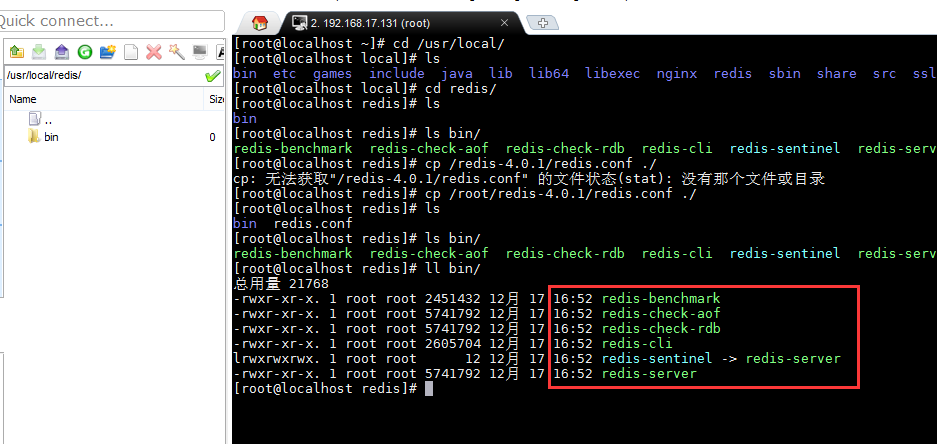
- redis-benchmark —-性能测试工具
- redis-check-aof —-AOF文件修复工具
- redis-check-dump —-RDB文件检查工具(快照持久化文件)
- redis-cli —-命令行客户端
- redis-server —-redis服务器启动命令
前端启动服务
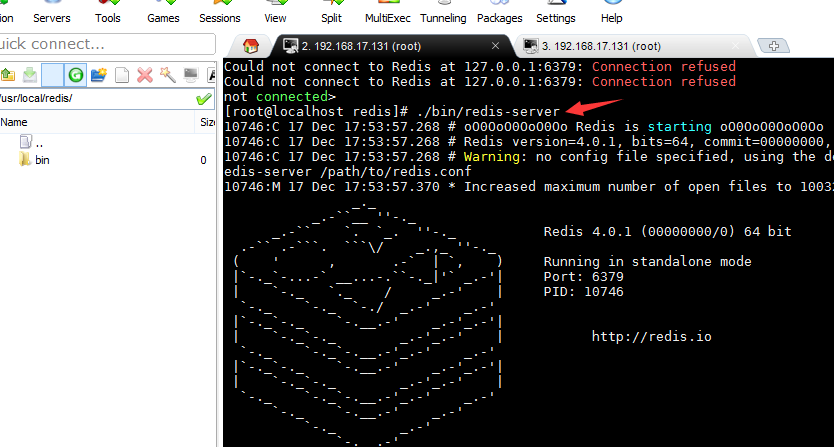
该启动方式有硬伤:无法进行集群部署
连接redis
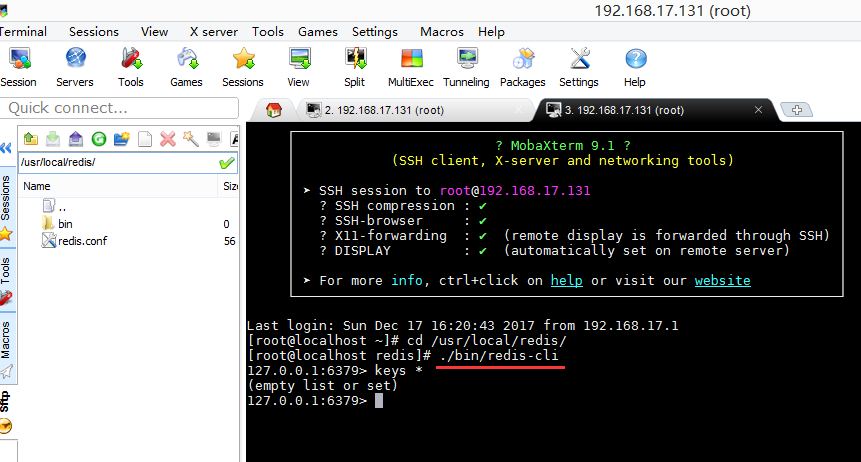
可以在上图的命令中加入参数 -h ip地址 -p 端口进行指定连接
后端启动服务
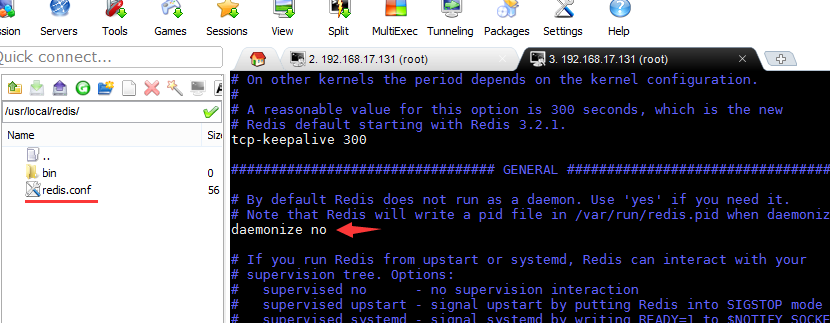
修改redis.conf配置文件的daemonize为yes即可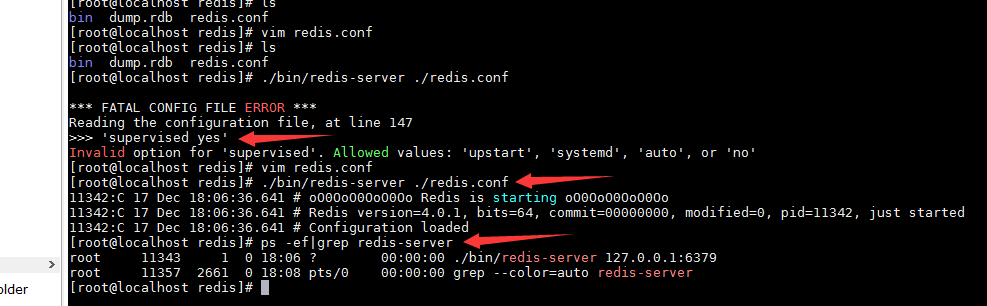
如果无法启动修改配置supervised yes为supervised no。按上图进行后端启动。
redis的5种数据类型
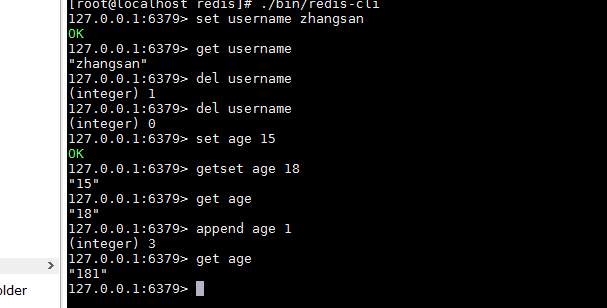
String
- 字符串类型是redis中最为基础、常用的数据存储类型,它在redis中是二进制安全的,value最多可以容纳的数据长度是512M。
- 二进制安全和数据安全是没有关系的。
- 关系型数据库,二进制是不安全的。会出现乱码丢失数据。编解码频繁。
以MySQL为例,它能指定数据的存储的字符集。服务器在拿到表中的数据时,很可能因为解码的码表不一致,导致出现数据的乱码。
redis直接存储的二进制数据,不会对数据再进行编解码操作。常用的命令
12345678set key value:赋值、修改操作,key相同则覆盖,新值覆盖旧值。del key:删除成功返回1(integer),key不存在返回0(integer)getset key value:先取后赋值incr key:递增1,非数字则报错decr key:递减1,非数字则报错append key value:类似StringBuffer的appendincrby key number:递增指定的数值decrby key number:递减指定的数值
hash
hash类型可以看成是具有String key和String value的map容器。非常适合于存储值对象的信息。占用的磁盘空间极少。其表现形式是{uname:”zhangsna”,age:”19”,sex:”man”}
常用的命令
|
|

list
链表结构,redis的操作中,最多的操作就是进行元素的增删,它的使用环境是做大数据集合的增删、任务队列。关于链表结构,可查看《Java的List、Set、Map容器》一文
常用的命令
|
|
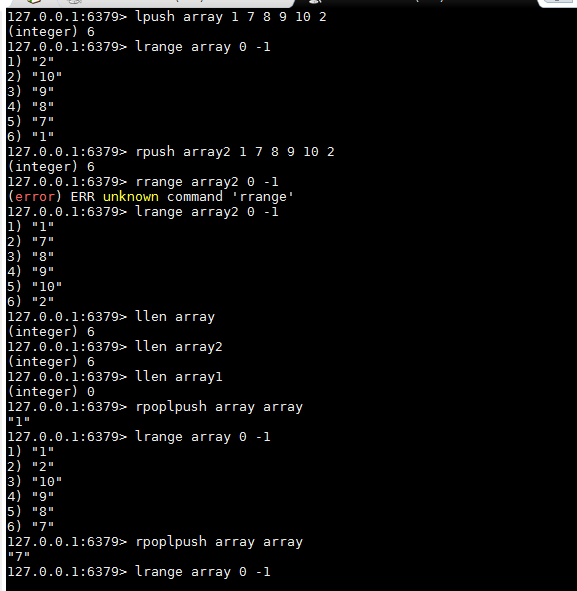
set
在redis中,可以将set类型看作为没有排序的字符集合。set可包含的最大元素数量是4294967295。set集合中不允许出现重复的元素,可在服务端完成多个set之间的聚合计算操作。效率极高。
常用的命令
|
|
有序set
有序,不重复。在集合元素上分配分数,每个元素都需要手动赋予一个分数。
常用的命令
|
|
通用命令
|
|
消息订阅与发布
subscribe channel:订阅频道
psubscribe channel*:批量订阅频道,*是通配符,订阅以channel部分的值为开头的频道
publish channel content:在指定的频道中发布消息
多数据库
redis默认有16个数据库,名称从0、1、2…15。在redis上所做的所有数据操作,默认在0号数据库上操作的。命令config get databases可查看数据的个数。数据库和数据库之间,是不能共享键值对。命令select 数据库名,切换数据库。move key dbname:将当前库的key移植到指定的数据库中。flushdb,清空当前数据库。flushall,清空redis服务器的数据。
事务
关系型数据库的事务,是为了保证数据的完整性、保证数据安全。可查看《关系型数据库的事务》一文。
redis的事务,是为了进行redis语句的批量执行。
multi:开启事务,用于标记事务的开始,其后执行的命令都将被存入命令队列。
exec:提交事务,执行批量化操作
discard:事务回滚,不执行批量化操作
redis的两种持久化策略
RDB
redis默认的持久化机制。安装目录下的dump.rdb文件。相当于照快照,保存的是一种状态。
优点:快照保存速度极快,还原数据速度极快。适用灾难备份。
缺点:小内存机器不适合使用。
RDB机制,符合要求就会照快照(随时随地启动),会占用一部分系统资源(突然的),很可能内存不足直接宕机。适用于内存
服务器正常关闭时,照快照。./bin/redis-cli shutdown
key满足一定条件,照快照。
redis.conf的配置,第二列是时间(秒),第三列是发生变化的key的个数。达到,则会在时间到达后照快照。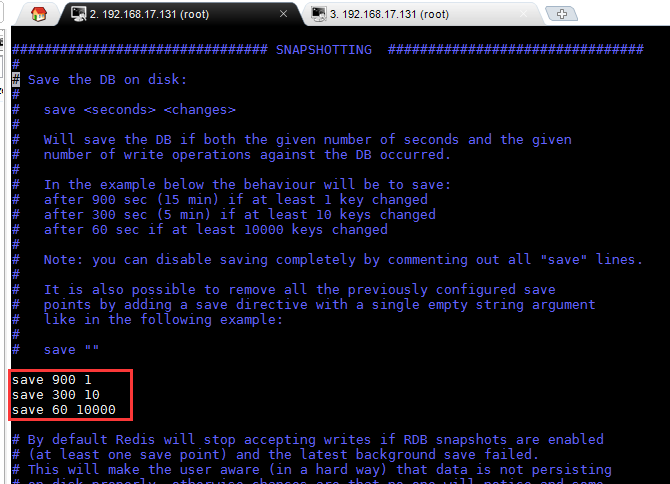
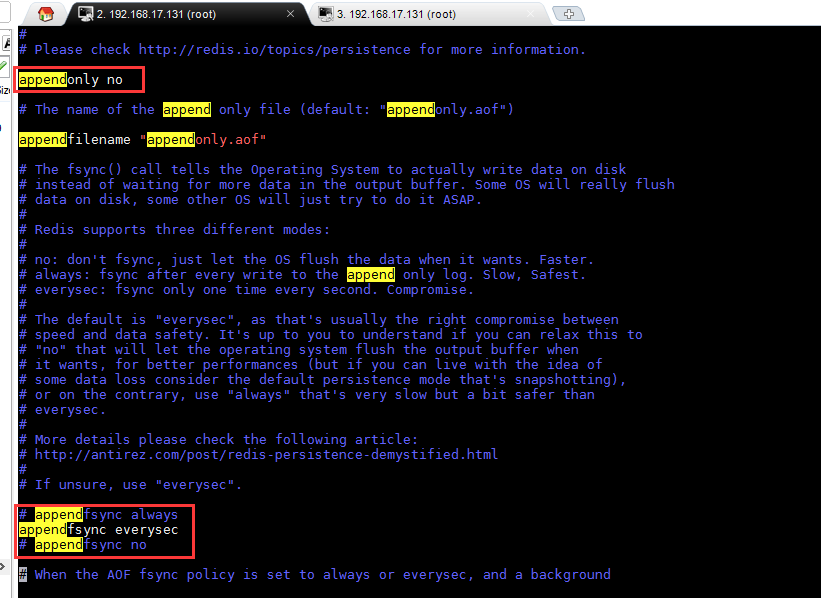
AOF
使用日志功能保存数据操作。默认AOF机制是关闭的。AOF操作,只会保存导致对应key发生变化的语句(增、删。改),保存的是语句不是数据。一个key在操作中可能出现10次的变化,如key保存的value变了,日志就会有对应的每次发生变化的语句。
优点:持续占用极少量的内存资源。
缺点:日志文件会特别大,不适用于灾难恢复。数据恢复效率远远低于RDB,适用于内存较小的计算机。
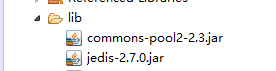
Java中访问redis
导包
示例代码
|
|

