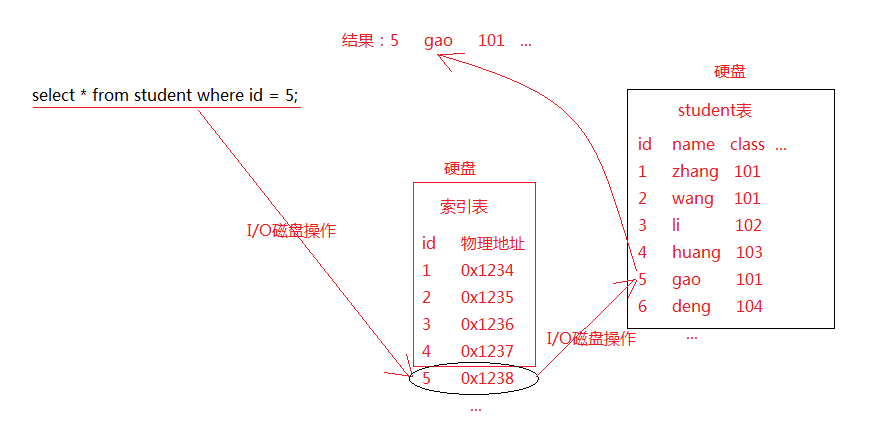
索引是对数据库,表中一列或多列的值进行排序的一种结构,使用索引可提高数据库中特定数据的查询速度。索引是一个单独的、存储在磁盘上的数据库结构,它包含着对数据表中所有记录的引用指针。MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。索引的本质:索引是数据结构。
存储引擎支持的索引
- MyISAM、InnoDB只支持BTree索引,Memory、Heap存储引擎可以支持Hash、BTree索引。
索引的分类
- 普通索引:MySQL中的基本索引类型,允许在定义所以的列中插入重复值和空值。
- 唯一索引:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。主键索引是一种特殊的唯一索引,不允许有空值。
- 单列索引:一个索引只包含单个列,一个表可以有多个单列索引。
- 组合索引:在表的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用。使用组合索引时遵循最左前缀集合。
- 全文索引:在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值。全文索引可以在CHAR、VARCHAR或TEXT类型的列上创建。只有MyISAM存储引擎支持全文索引。
- 空间索引:是对空间数据类型的字段建立的索引。创建空间索引的列,不允许有空值。只有MyISAM存储引擎支持空间索引。
索引的优点
- 通过创建唯一索引,可以保证数据库表中每一行数据的唯一性。
- 可以大大加快数据的查询速度,这也是创建索引的最主要原因。
索引的缺点
- 创建索引和维护索引要耗费时间,并且随着数据量的增加所耗费的时间也会增加。
- 索引需要占用磁盘空间,即物理空间。如果有大量的索引,索引文件可能比数据文件更快达到最大文件尺寸。
- 当对表中的数据进行增加、删除和修改时,索引也要动态的维护,降低了数据的维护速度。
InnoDB存储引擎的索引实现
- InnoDB存储引擎使用B+Tree作为索引结构。在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
- InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键。如果没有显示指定主键,InnoDB会为每一行生成一个隐藏的6个字节的ROWID,并以此作为主键。《MySQL的存储引擎》一章所提到的。
- 在使用InnoDB存储引擎时,如果没有特别的需要,使用一个与业务无关的自增字段作为主键则是一个很好的选择。
聚集索引与非聚集索引
- 聚集索引表记录的排列顺序与索引的排列顺序一致,优点是查询速度快,因为一旦具有第一个索引值的纪录被找到,具有连续索引值的记录也一定物理的紧跟其后。
聚集索引的缺点是对表进行修改速度较慢,这是为了保持表中的记录的物理顺序与索引的顺序一致,而把记录插入到数据页的相应位置,必须在数据页中进行数据重排,降低了执行速度。类似于数组。 - 非聚集索引指定了表中记录的逻辑顺序,但记录的物理顺序和索引的顺序不一致,聚集索引和非聚集索引都采用了B+Tree的结构。非聚集索引比聚集索引层次多,添加记录不会引起数据顺序的重组。类似于链表。
聚集索引和非聚集索引的区别
- 两者的根本区别是表记录的排列顺序和与索引的排列顺序是否一致。
- 聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个。
- 聚集索引存储记录是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储并不连续。
- 聚集索引查询数据速度快,插入数据速度慢;非聚集索引反之。
索引的设计原则
- 索引并非越多越好,这里不再阐述原因。
- 避免对经常更新的表进行过多的索引,索引中的列尽可能少,而对经常用于查询的字段应该创建索引。
- 数据量小的表最好不要使用索引。查询花费的时间可能比遍历索引的时间还要短。
- 索引的选择性较低时,不应建立索引。
索引的选择性
所谓索引的选择性(Selectivity),是指不重复的索引值(也叫基数,Cardinality)与表记录数(#T)的比值:Index Selectivity = Cardinality / #T
显然选择性的取值范围为(0, 1],选择性越高的索引价值越大,这是由B+Tree的性质决定的。
数据如下图: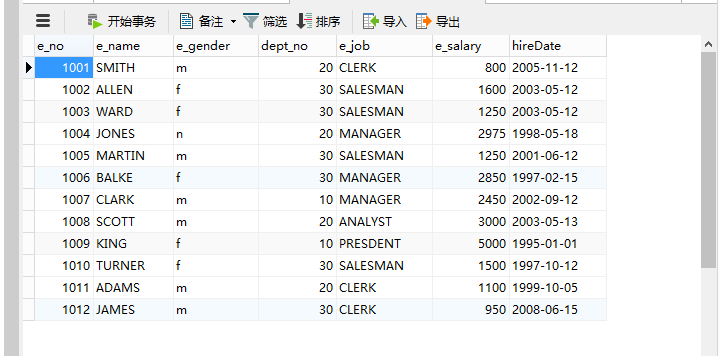
以dept_no做为建立索引的选择性:
SELECT count(DISTINCT(dept_no))/count() AS Selectivity FROM employee;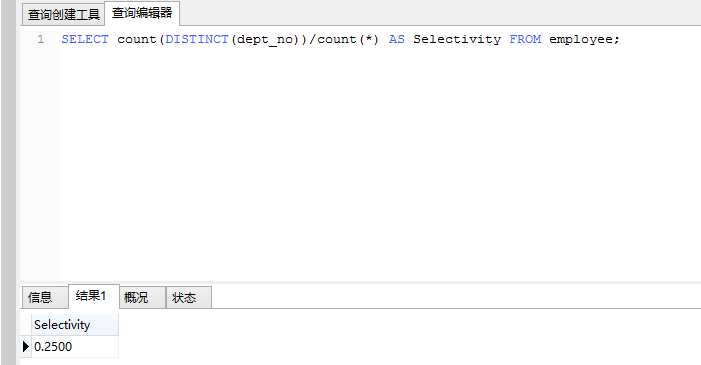
以e_no做为建立索引的选择性:
SELECT count(DISTINCT(e_no))/count() AS Selectivity FROM employee;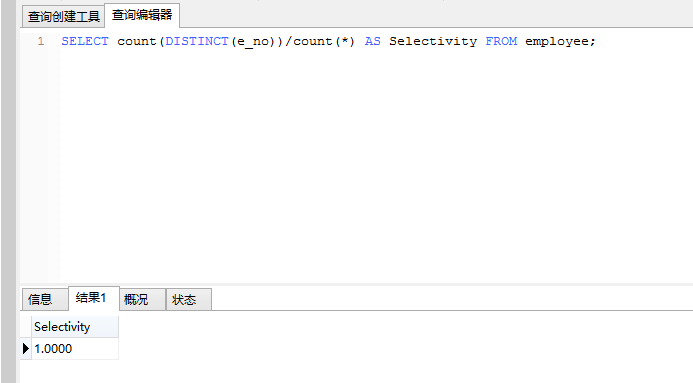
可以对比出,在e_no列上建立索引的选择性更高。
当在e_no列上建立索引后,可以使用EXPLAIN语句查看索引是否正在使用。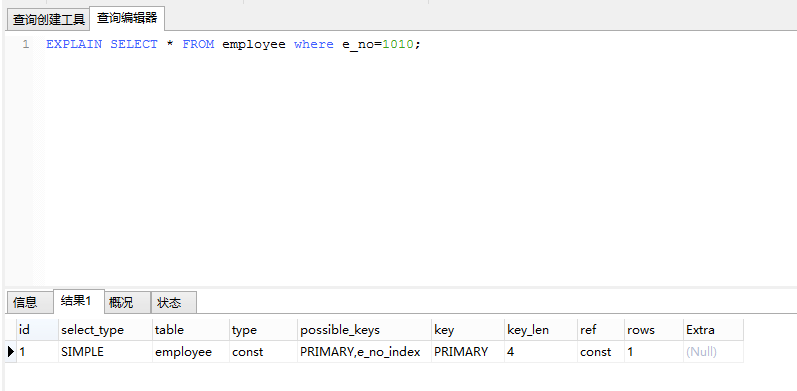
EXPLAIN语句输出结果的各个行解释
|
|

