数组的特点
- 数据多了用对象存储,对象多了就用数组或集合存储。使用容器的最基本规则。
- 数组的长度必须事先指定,且一旦定义就不能再更改。
- 数组的存储的数据类型是固定的类型,单一类型数据的存储。
- 数组的内存分配,一次性分配一片连续的内存空间。连续的内存空间有多大,就在于数组的长度有多长。
为什么会出现这么多的容器呢?
因为每一个容器对数据的存储方式都有不同,这个存储方式称之为:数据结构。
List中常用的容器
该容器体系存放元素是有序的,元素可以重复。因为该集合体系有索引。List集合判断元素是否相同,依据的是元素的equals()方法。如果需要依据自己的条件进行判断是否为同相同元素,则需要重写equals()方法。
ArrayList
- 底层使用数组结构。elementData就是该集合存放数据的地方。分配的内存地址空间是连续的一片。

- 特点:查询速度很快。但是增删稍慢。线程不安全。
拿着角标,即可获取到元素。就类似与现实生活中的门牌号。”去找到小明家”,这么多叫小明的,怎么找?”去找到小明家,他住XX街5号”。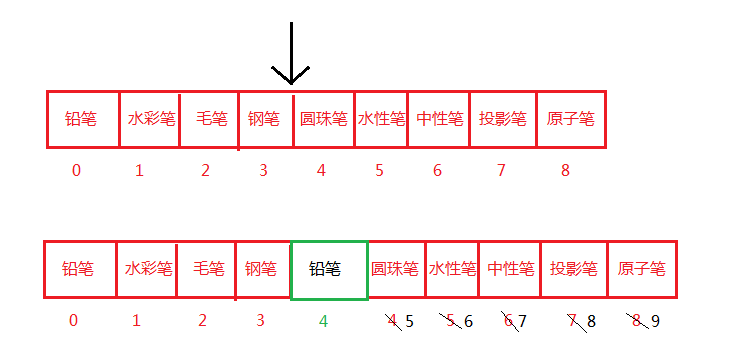
在角标4的位子插入一个新元素,意味该角标位后面的所有元素都需要挪动一下。假设集合的容量很大,1000、10000、100000或者1000000(当然不能超过int的最大值),就这一个简单的操作,对内存的消耗是非常大的。删除也是同理。 - 自动扩容,每次都是把原来的数组复制进一个新数组中,新数组的长度增长量是原来的size的50%。看一下ArrayList的源码:
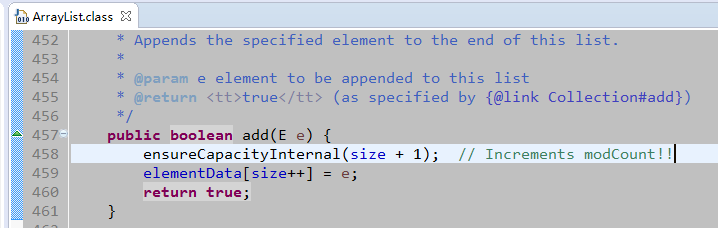
自动扩容是发生在添加的时候。容量为当前size+1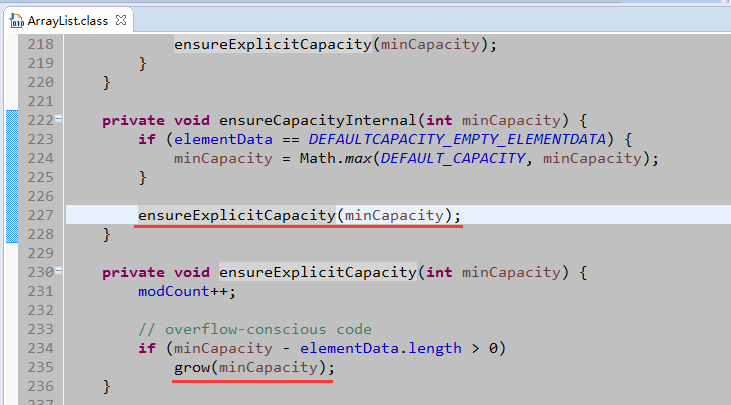
modCount这里不做详细说明,ConcurrentModificationException异常产生的原因就是因为它。如果size+1减去当前元素数组的长度大于0,则表示需要扩容。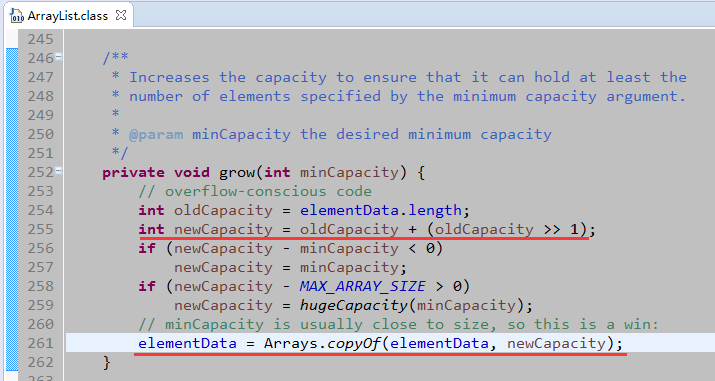
第一个红线,新的容量为旧的容量加上旧的容量值右移一位。int数值的二进制右移一位,就是原来数值的一半。所以,扩容的增长量是原来的size的50%。第二个红线,调用Arrays.copyOf()方法。如下图,在原数组的基础上,新增一个数组。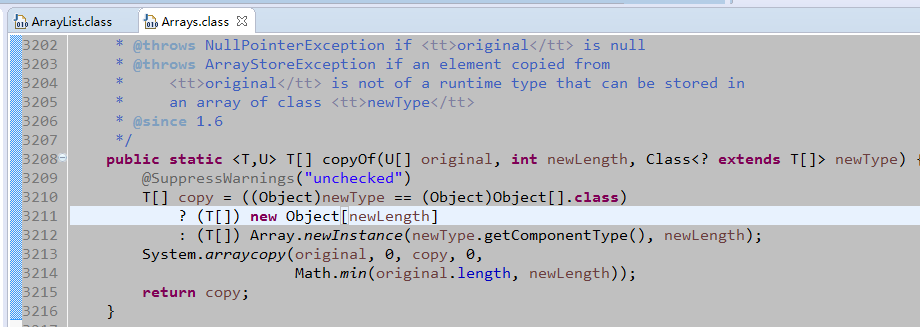
LinkedList
- 底层使用链表结构,双链表。分配的内存地址空间是可以是碎片化空间。
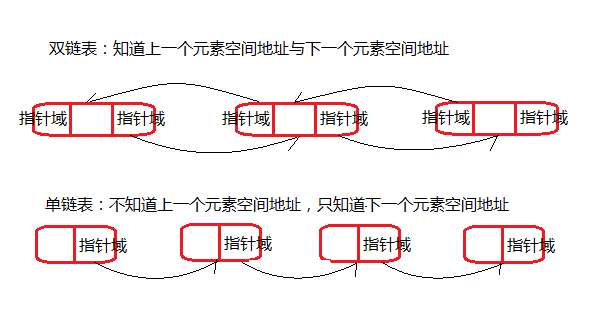

- 特点:增删很快,查询很慢,线程不安全。
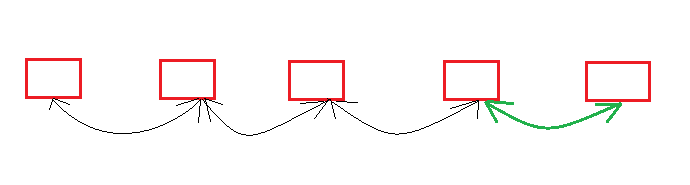
增加:让最后一个元素的next记录住当前新增元素的空间地址,并当前新增元素的prev记录上一个元素,last为当前元素地址。删除也是同理,直接让上一个元素的next为null,last为上一个元素地址。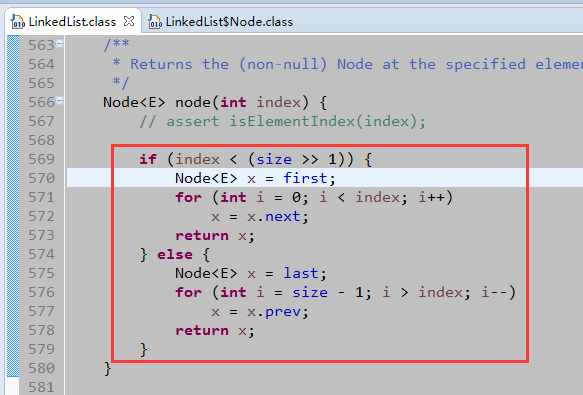
上图,get(int index)和remove(int index)方法中,折半来进行顺序查找元素。ListIterator
List集合特有的迭代器。在迭代时,不可以通过集合对象的方法操作集合中的元素。因为会发生ConcurrentModificationException异常。所以,在迭代器时,只能用迭代器的方式操作元素,可是Iterator方法是有限的,只能对元素进行判断,取出,删除的操作,如果想要其他的操作如添加,修改等,就需要使用其子接口,ListIterator。该接口只能通过List集合的listIterator方法获取。实现简单的队列
123456789101112131415161718192021222324252627class MyQueue {private LinkedList<Object> link;MyQueue() {link = new LinkedList<Object>();}public void myAdd(Object obj) {link.offerFirst(obj);}public Object myGet() {return link.pollLast();}public boolean isNull() {return link.isEmpty();}}public class LinkedListTest {public static void main(String[] args) {MyQueue mq = new MyQueue();mq.myAdd("java01");mq.myAdd("java02");mq.myAdd("java03");mq.myAdd("java04");while (!mq.isNull()) {System.out.println(mq.myGet());}}}
Set中常用的容器
元素是无序(存入和取出的顺序不一定一致),元素不可以重复。底层都是使用Map集合存储元素。
HashSet
- 底层数据结构是哈希表,使用HashMap存储元素,只使用了HashMap的Key部分,未使用Value部分。是线程不安全的。
HashSet是如何保证元素唯一性的呢?
|
|
- hashCode值采用name.hashCode() + age * 27
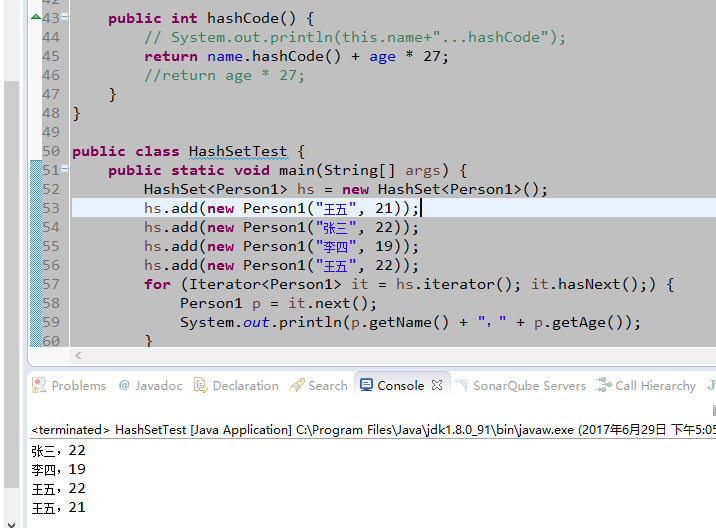
- hashCode值采用age * 27,age相同就会进行比较,因最终equals不为true,视为不同元素。
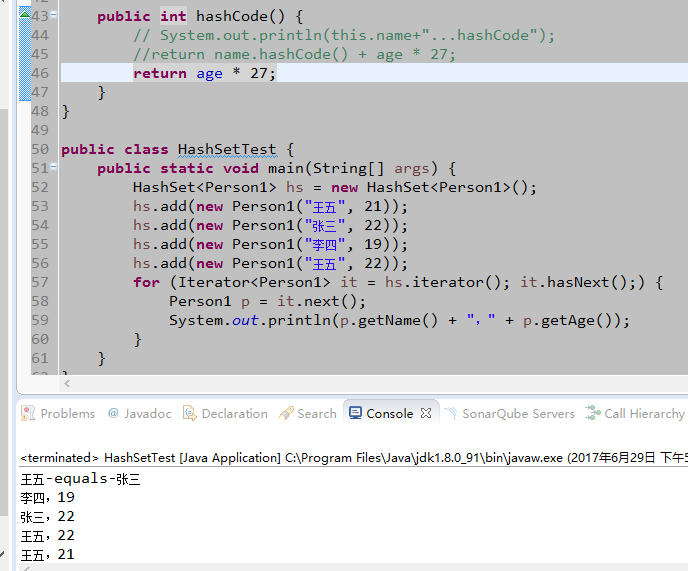
- hashCode值采用age * 27,age相同就会进行比较,比较了两次,equals为true,视为相同元素,不存入。
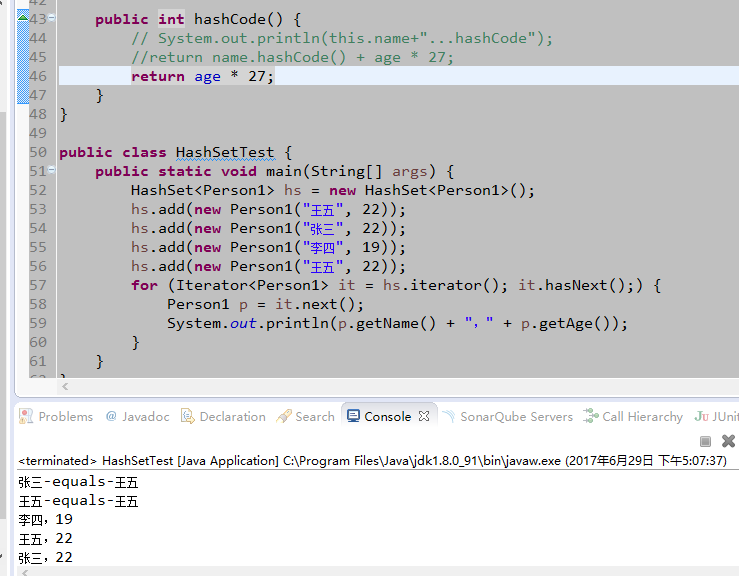
结论
HashSet是通过元素的两个方法,hashCode和equals来完成。
如果元素的HashCode值相同,才会判断equals是否为true。
如果元素的hashcode值不同,不会调用equals。
注意,对于判断元素是否存在,以及删除等操作,依赖的方法是元素的hashcode和equals方法。
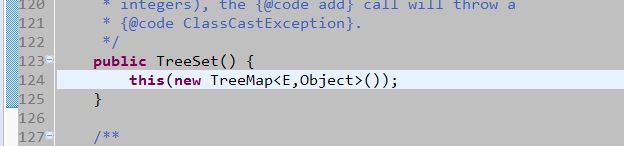
TreeSet
- 底层数据结构是二叉排序树,使用TreeMap存储元素。是线程不安全的。使用TreeMap中的K保存数据,V是一个常量Object对象。
- 特点:可以对集合内的元素进行排序。
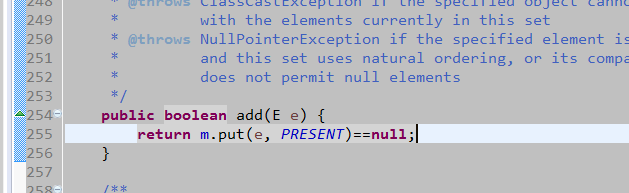
- 默认的排序规则是:按自然排序(左小右大)。下图是put方法中的一段代码。
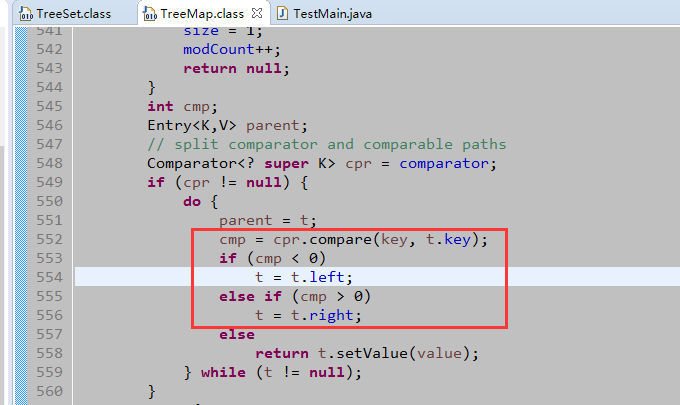
排序重点,比较器或比较接口
|
|
- TreeSet保证元素唯一性的依据就是compareTo()方法的return值。大小判断的依据也是该方法的返回值。正数代表大,负数代表小,0则表示是相同元素。1234567891011//使用匿名内部类的方式,传递比较器TreeSet<String> ts = new TreeSet<String>(new Comparator<Student>(){public int compare(Student o1, Student o2) {//自行定义比较规则int num = o1.getName().compareTo(o2.getName());if (num == 0)// 对象包装类调用compareTo()方法,判断次要条件return new Integer(o1.getAge()).compareTo(new Integer(o2.getAge()));return num;}});
Map中常用的容器
上面已经说过。Set集合底层就是使用Map集合存储。Map集合被使用是因为具备映射关系。Map集合中,如果键相同,就会出现新值覆盖旧值。
Map集合的取值原理:将Map集合转成Set集合,再通过迭代器取出。取值的两种方式:
- entrySet():返回值类型为Set
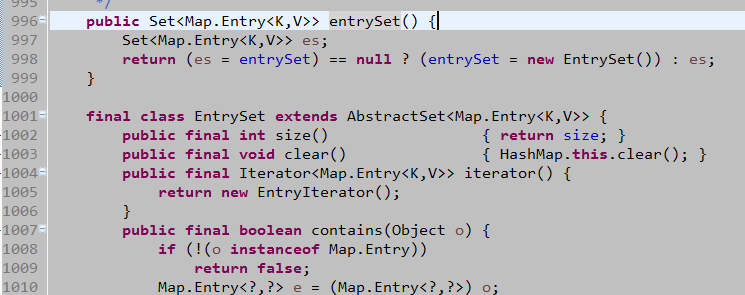
- keySet():返回值类型为Set
;K为Key的数据类型。该方法将Map集合中所有的键存入到Set集合中,因为Set具备迭代器。所以可以用迭代方式取出所有的键,再根据get(key),获取每一个键对应的值。 下图为HashMap对keySet()的具体实现。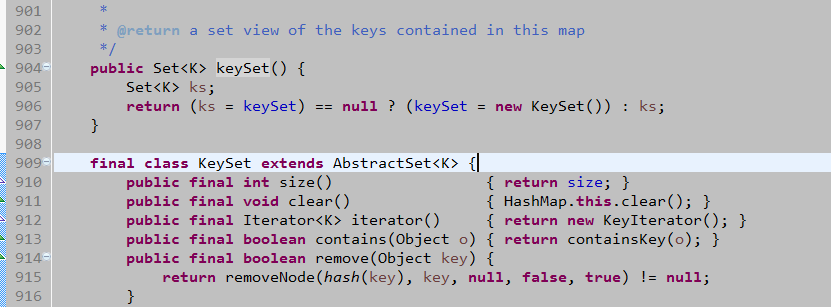
Hashtable
底层使用哈希表数据结构,线程安全,效率低。内部实现使用synchronized关键字,同步方法。(有很多,可自行查看源码)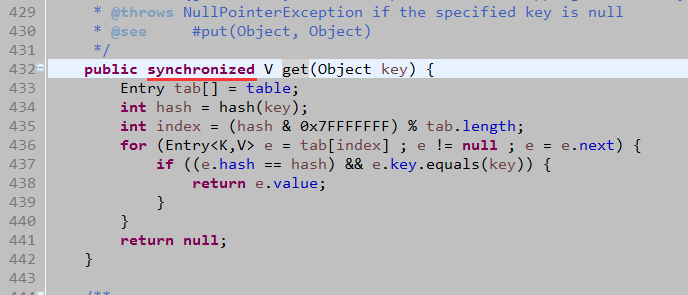
不可以存入null键、null值。(key为null的时候,调用.hashCode会直接抛NullPointerException异常,所以没有再做判断)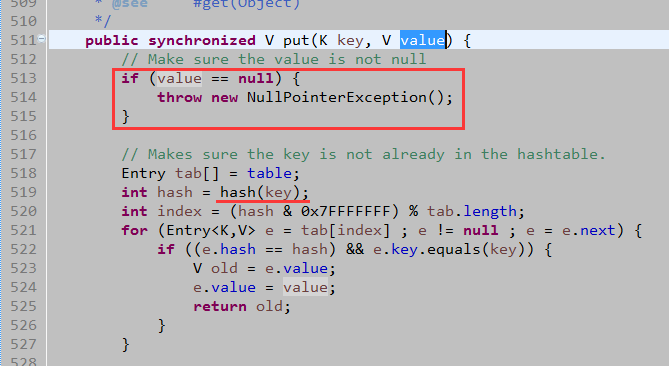

HashMap
底层使用哈希表数据结构,允许存入null键、null值,线程不安全,效率高。(并发操作时,可能会发生内存溢出。后期再具体来谈使用HashMap出现内存溢出的情况。)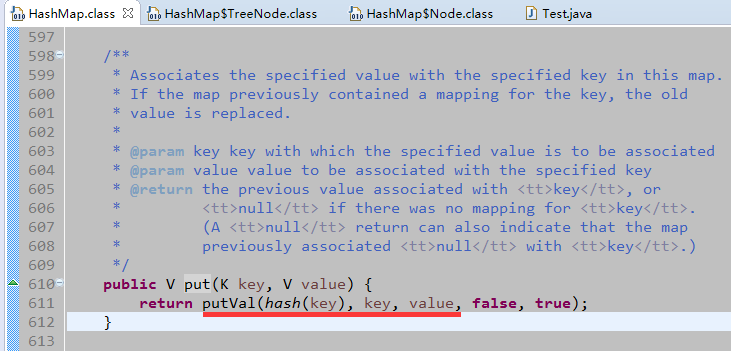
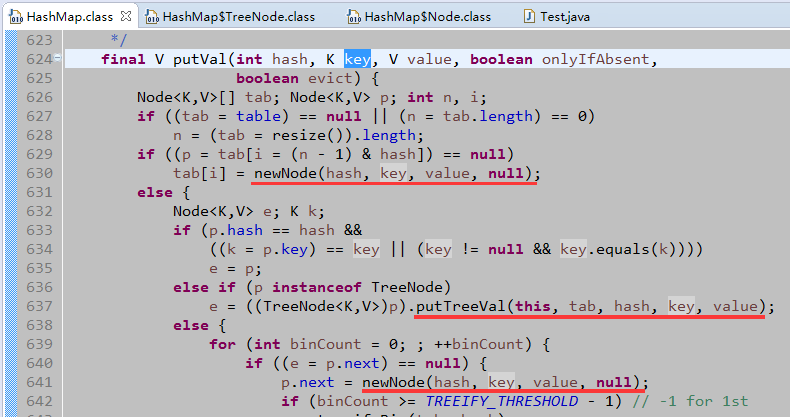
看到这里,其实也就明白了为什么HashMap允许存入null键、null值了。因为Key、Value是作为一个Node对象的属性来被存储的。而更有意思的是那个Node对象,采用的是树结构。TreeNode是其子类,而且还是使用红黑树,有意思吧。红黑树其中一个特点就是,子树之间的高度差不超过1。这样保证了元素的饱和存储。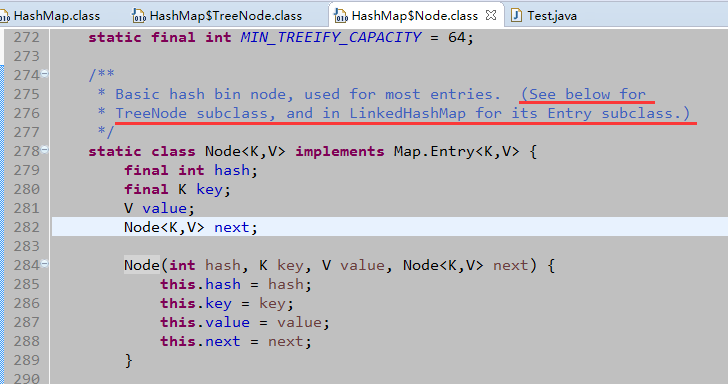
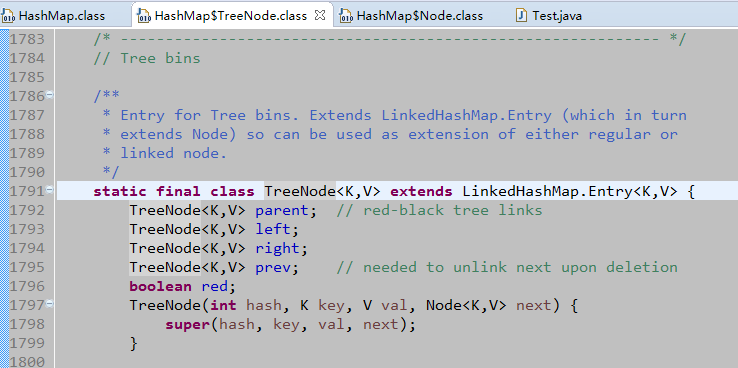
TreeMap
底层使用二叉树数据结构,线程不安全,可以用于给集合中的Key进行排序。compare()比较的就是key